A Survey of Large Language Models
https://github.com/RUCAIBox/LLMSurvey
语言建模(LM)的发展历史
SLM(统计语言模型,统计学习方法)-> NLM(神经语言模型,特征学习方法)-> PLM(Pre-training Language Model) -> LLM(Large Language Model)
LLM与PLM的几点区别:
- LLM表现出涌现能力(在小型模型中不存在但在大型模型中产生的能力),规模提升时,性能显著提高
- LLM改变了人类使用人工智能算法的方式(API)
- LLM的发展不再区分研究和工程。为了开发出有能力的LLM,研究人员必须解决复杂的工程问题,他们需要与工程师合作或成为工程师。
Question
- 为什么LLM相较于PLM能力提升如此明显?
- 研究界难以训练出有能力的LLM,而工业界并不会向公众透露LLM的训练细节
- 如何将LLM与人类价值观或偏好保持一致?
面对如此挑战,研究者无法深入理解LLM的基本原理。
本文从四个方面阐述LLM的进展:
- 预训练(如何预训练出一个有能力的 LLM)
- 适配微调(如何从有效性和安全性两个角度有效地微调预训练的 LLM)
- 使用(如何利用 LLM 解决各种下游任务)
- 能力评估(如何评估 LLM 的能力和现有的经验性发现)
前两者是从LLM训练的角度展开的,后两者是从LLM应用角度展开的。
预训练
数据收集和处理->模型架构->优化LLM训练技巧
适配微调
预训练后,LLM需要进一步适配到特定的目标中。
方法如下。
指令微调(instruction tuning)
增强大模型在特定目标中的表现
- 构建格式化实例:格式化已有数据集、格式化人类需求
- 微调策略:指令多样性、结合指令微调和预训练
对齐微调(alignment tuning)
将LLM的行为与人类价值观对齐
对齐标准:有用性、诚实性、无害性
用途最广泛的技术:RLHF(基于人类反馈的强化学习)
RLHF系统的三个关键组件:要对齐的PLM、从人类反馈中学习的奖励模型,以及训练 LM 的 RL 算法。
要对齐的PLM
使用现有参数进行初始化
人类反馈中学习的奖励模型
经过微调的 LM 或使用人类偏好数据重新训练的 LM (通常采用参数量较小的模型)
训练LM的RL算法
PPO算法——现有工作中广泛使用的RL对齐算法
除此之外,还有LoRA等用于LLM参数高效微调的算法。
使用
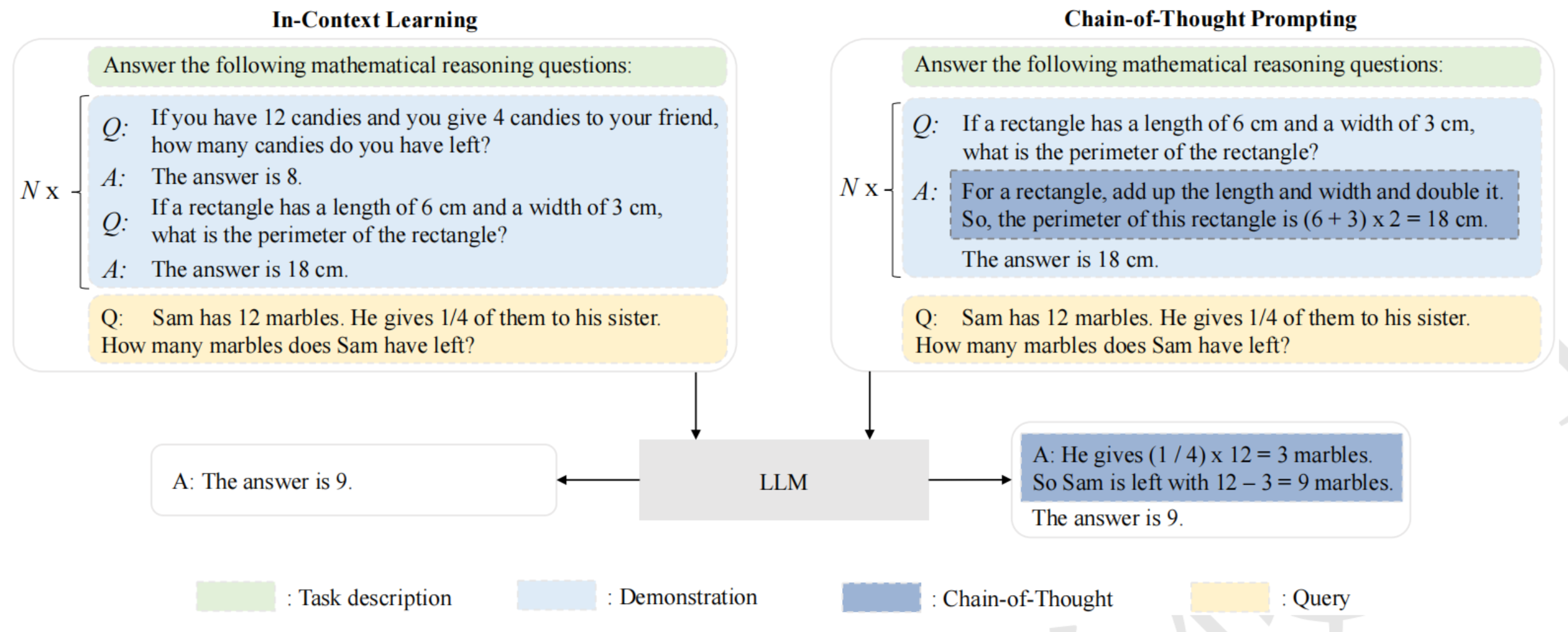
上下文学习(in-context learning, ICL)-Retrieval
经过预训练后,LLM可以在不更新的情况下展现出较好的ICL能力。
思维链提示(chain-of-thought prompting)-Reasoning
能力评估
大模型的问题:
幻觉
生成的信息与现有来源相冲突(内在幻觉)或无法通过现有来源验证(外在幻觉)。
知识实时性
面对需要使用比训练数据更新的知识的任务
微调 LLM 的成本非常昂贵的,而且增量训练 LLM 非常可能导致灾难性遗忘问题。
ChatGPT使用检索插件来访问最新的信息源,将提取的信息融入上下文中,然而该方法仍然停留于表面层次。一些实验揭示,直接修改内在知识或将特定的知识注入 LLM 是很困难的

